
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web
Published:
Conference
ECCV 2020
Authors
- Arjun Majumdar
- Ayush Shrivastava
- Stefan Lee
- Peter Anderson
- Devi Parikh
- Dhruv Batra
Contributions
- Developed VLN-BERT, a visiolinguistic transformer-based model for scoring path-instruction pairs. Shows that VLN-BERT outperforms strong single model baselines from prior work on the path selection task - increasing success rate (SR) by 4.6 absolute percentage points.
- Demonstrated that in an ensemble of diverse models VLN-BERT improves SR by 3.0 absolute percentage points on “unseen” validation, leading to a SR of 73% on the VLN leaderboard.
- Ablated the proposed training curriculum, and find that each stage contributes significantly to the final outcome, with a cumulative benefit that is greater than the sum of the individual effects.
- Provides qualitative evidence that our model learns to ground object references. Specifically, using gradient-based methods visualizes how image-region importance shifts under modifications to the instructions given to our model, demonstrating reasonable responses to these interventions. For example, if we modify the instruction ‘Walk down the stairs, then stop next to the fridge. ’by removing‘stop next to the fridge’ we observe that image regions containing the fridge become less important
Interesting Concepts
- BERT
- VIL-BERT
- VLN-BERT
- Leveraging transfer learning
- training methods
Approach
- Vision-and-Language Navigation as Path Selection
- Modeling Instruction-Path Compatibility
Architecture
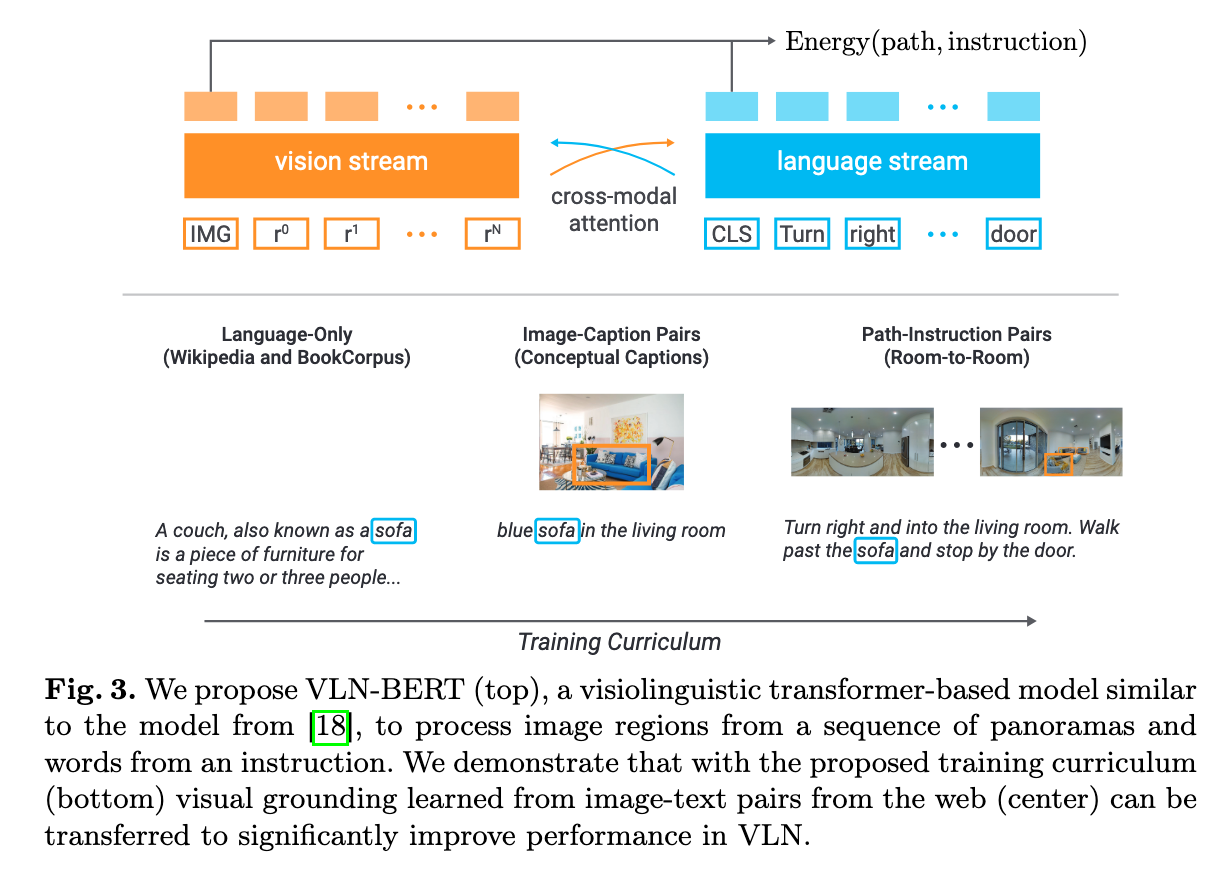
Dataset
- Matterport3D
Metrics
- Success rate (SR)
- Oracle Success rate (SR)
- Navigation error (NE)
- Path length (PL)
- Success rate weighted by path length (SPL)