Visual Question Answering using CLIP
Gunjan Aggarwal, Harsh Maheshwari, Ashwin Pathak, Ram Ramrakhya
*lexicographical ordering
Introduction
One of the tasks humans efficiently do is make sense of the visual information around us. However, we communicate our understanding of the visual information using natural language. Vision and Language usually go hand-in-hand for a lot of tasks we perform daily and thus it is important for machines to be able to do so as well. Visual Question Answering, introduced in [1], is one such task where the problem is to select one of many possible answers given an image and a question associated with the image. See figure 1 for an example. The VQA v2 [2] dataset has 82,783 training images which lead to 443,757 questions in total. Each question was answered by 10 humans generating a total of 4,437,570 answers. There has been a lot of interest in multi-modal research, especially on vision and language modalities recently. CLIP [3] accelerated this research by releasing a large self-supervised trained model on a huge corpus of image, text pairs. Thanks to the easy access to the trained model, it has been used for various vision and language tasks such as zero-shot image classification [3], zero-shot text-to-image generation [4] and many others [5, 6]. We propose to leverage CLIP pre-trained embedding space to solve the VQA task.

Problem definition
Giving machines the ability to understand and communicate the understanding through question answering is an important and impactful task with a lot of social benefits like helping visually impaired humans [7]. However, it is often difficult and expensive to train huge models on large datasets. We propose to leverage the already available pre-trained vision-and-language CLIP model for the VQA task efficiently.
Methods
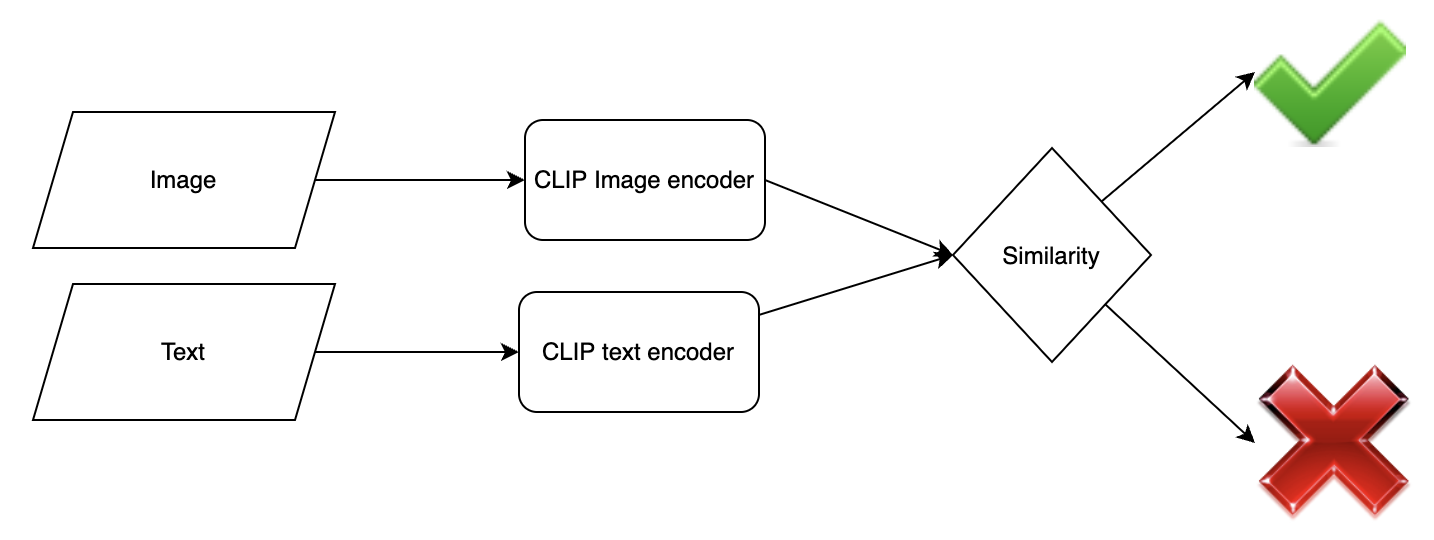
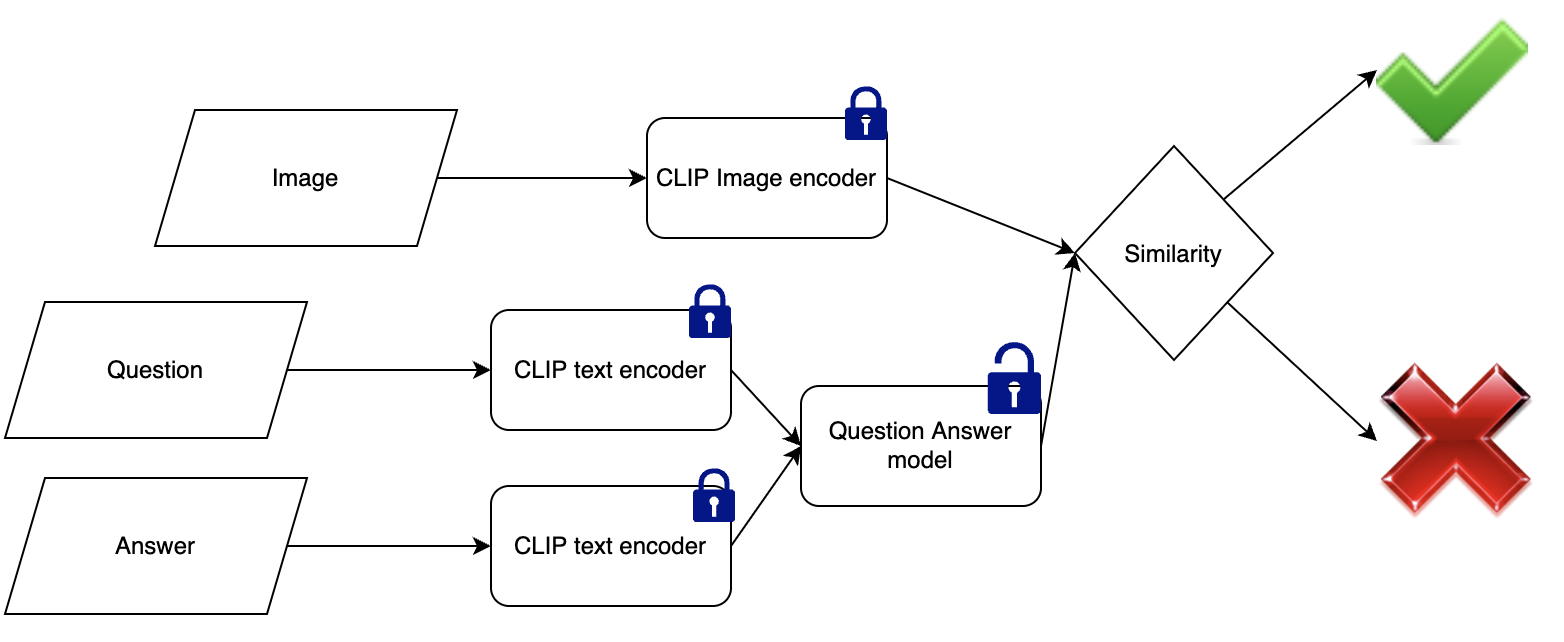
Supervised section: CLIP has a visual encoder and a text encoder trained to align the vision and text embeddings when the inputs are aligned (see figure 2). We plan on adding a question-answer encoder that transforms the text embeddings from the question and the correct answer to align well with the image embedding (figure 3).
Unsupervised section: While inference, the above approach would require encoding all possible answers to select the one which aligns the most. However, this is inefficient as the answers can be filtered out based on the question type. For example, the answer to “What color is …?” can never be “apple”. Thus if we are able to form clusters of answer types, we can use these clusters to filter out potential answers and reduce the computation cost while inference.
Data Preprocessing
To enable zero-shot transfer we generate question-answer pairs using top 1000 answers from VQA train split, we use the top 1000 most frequent answers to generate question-answer pairs. For each question-answer pair we generate a corresponding text prompt by using fixed question separator token (“Q:”, “Question:”, etc) and answer separator token (“A:”, “Answer:”, etc), for example “Question: What color is ….? Answer: apple”. Here’s the preprocessing we perform for image input to CLIP:
- Resize the input image to length of shortest edge
- Center crop the image to 224x224
- Normalize the image To save training and evaluationg time for our model we precompute the image features for the static VQA dataset and save it on disk.
Since VQA dataset is huge (1,105,904 questions and 11,059,040 ground truth answers), and we have limited compute to perform fine-tuning experiments over such a large dataset, we further pre-process the data to use a subset for fine tuning. Specifically, for training: we pre-process the data to use a subset such that the questions are focused on color sub-cateogries: [‘what color is the’, ‘what color is’, ‘what color are the’, ‘what is the color of the’, ‘what color’] These have 268 unique possible answers. For validation, we again use a subset such that the questions are focused on color sub-cateogries, but in addition also check that the possible answer is in the set of 268 unique answers from our training set to avoid class distribution shift. In adiditon to helping with tackling resource limitation, this split also helps us utilize the power of CLIP model better as the solution class is not very random.
Results and Discussion
Unsupervised
To establish baselines to compare with our approach we start with experiments on zero-shot transfer of CLIP for VQA.
Zero-Shot VQA using CLIP
In this approach we use pretrained CLIP text and image encoders to predict answer for the target question. To enable zero-shot transfer we generate question-answer pairs using top 1000 answers from VQA train split, we use the top 1000 most frequent answers to generate question-answer pairs. For each question-answer pair we generate a corresponding text prompt by using fixed question separator token (“Q:”, “Question:”, etc) and answer separator token (“A:”, “Answer:”, etc), for example “Question: What color is ….? Answer: apple”. Each question-answer prompt along with the image is passed through CLIP text and visual encoder to generate a similarity score, we then choose answer from the question-answer prompt with maximum similarity score as predicted answer. In these experiments, we focus on engineering the best prompt for zero-shot transfer of CLIP for VQA.
| Prompt | other | number | yes/no |
|---|---|---|---|
| < question > + “ “ + < answer > (Top 1000) | 7.01 | 0.06 | 0.07 |
| < question > + “ “ + < answer > (Top 3000) | 4.50 | 0.04 | 0.04 |
| Question: < question > + “ “ + Answer: < answer > (Top 1000) | 6.65 | 0.07 | 0.06 |
(1.) CLIP Zero-Shot transfer on VQA sampled val. Accuracy for per question type
Table 1. shows the results of zero-shot transfer of CLIP on VQA val split. First, we use a simple prompt that just appends
Supervised
In order to improve over our unsupervised baselines we implement 2 supervised baselines. We propose a vanilla N-way classification baseline that uses frozen CLIP represntations to establish a upper bound for comparison of our Question-Answer embedding alignment model.
Question-Answer embedding alignment model
To improve our zero-shot CLIP baseline we propose a Question-Answer embedding alginment approach. We sample the batches for training similar to contrastive style training where we sample 1 positive example and n-1 negative examples for each question. Sampling batches in this form allows our model to learn to map embeddings for relevant answers closer in embedding space and push the embedding that are not relevant far apart. We experiment across different hyper-parameter value for choosing n-1 negative samples as shown in the table. The steps to train the classifier are as follows :
- Obtain frozen CLIP representations for Question text and Answer text as input.
- Train a 2-layer MLP which takes these representations and fuses them into a single Question-Answer candidate representation.
- Use both of these representations for classification using ground truth. We further use two approaches for hidden representation of the image and text embeddings :
- Approach#1 : Use this joint learned representation as a query representation for the frozen CLIP image representation (Figure 4).
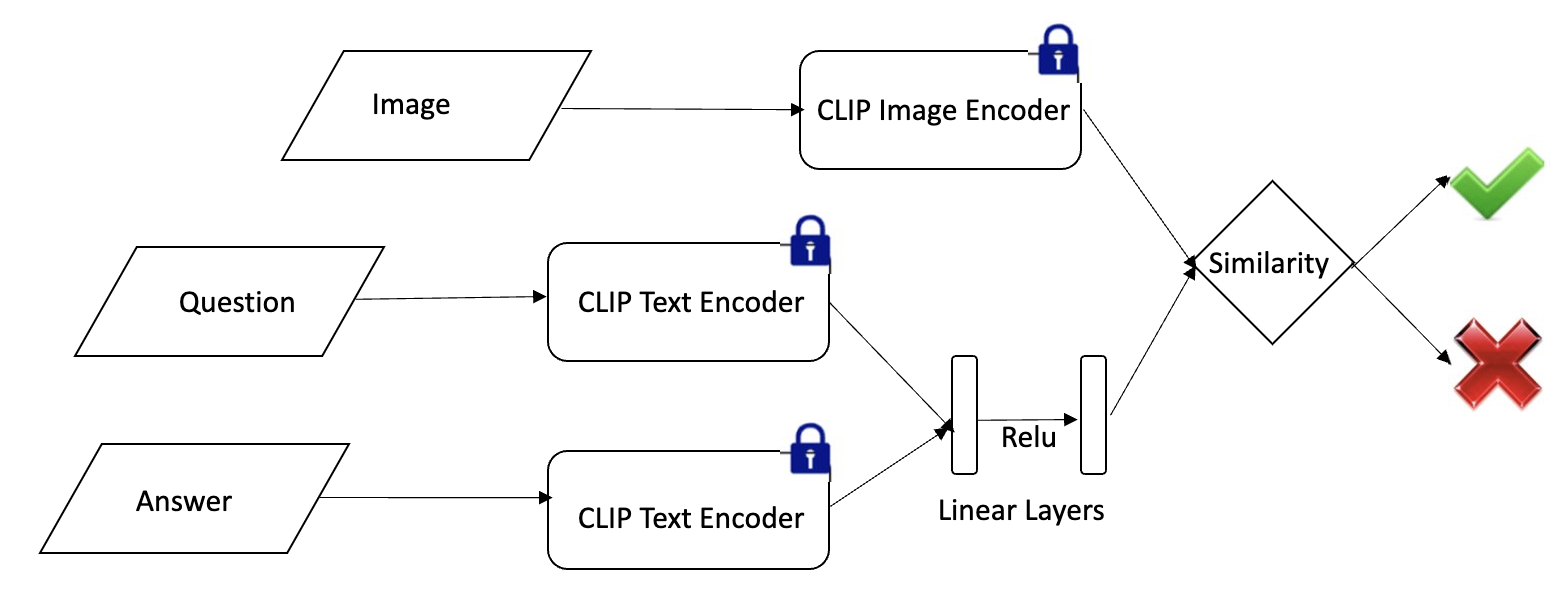
- Approach#2 : Concatenate joint Question-Answer embedding and Image embedding and pass them through a linear layer that learns similarity of these representations (Figure 5).
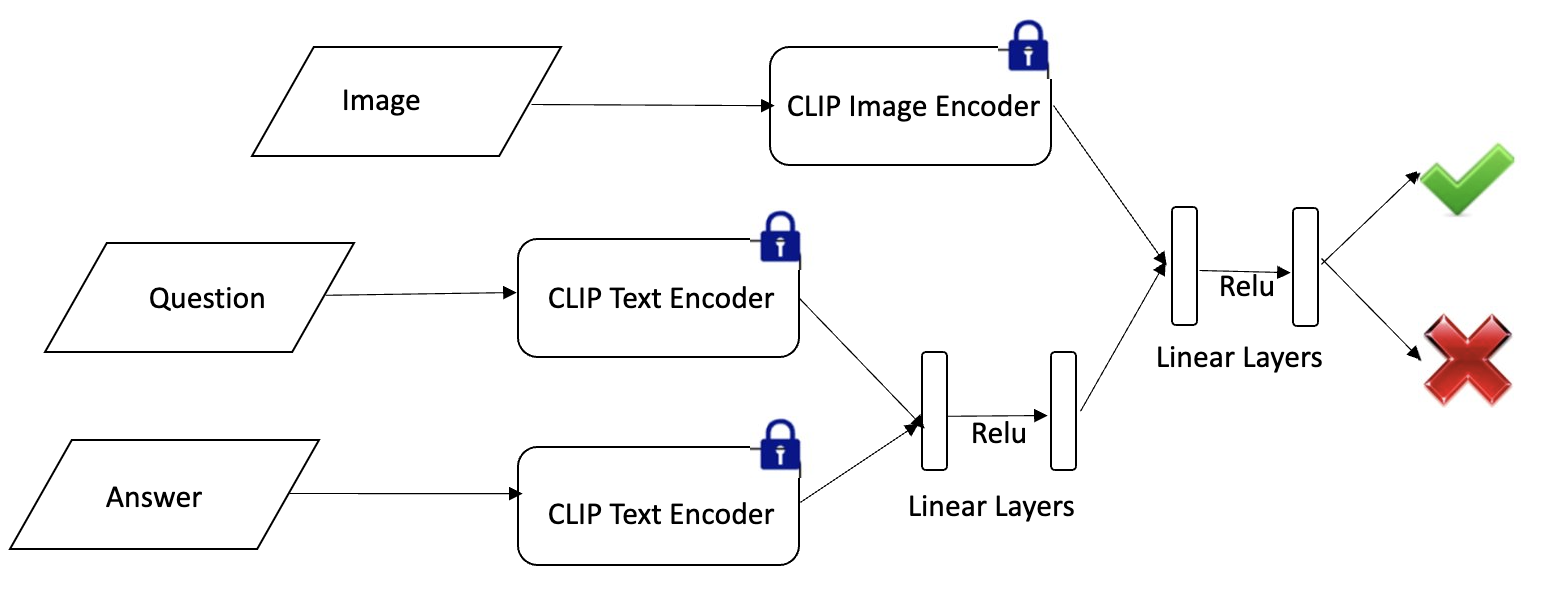
| Approach | Num candidates | Overall accuracy |
|---|---|---|
| #1 | 5 | 24.69 |
| #1 | 10 | 4.50 |
| #2 | 5 | 36.75 |
| #2 | 10 | 9.43 |
(2.) Question-Answer alignment model performance on VQA sampled val
Table 2. shows the results of Question-Answer alignment model on VQA sampled val split. We ablate on different values of num candidates we select for our approach. Using 5 candidates for negative sampling we achieve 24.69% accuracy on the evaluation split which is 20.19% better when compared to using 10 candidates. Similar trends can be observed for Approach#2 as well. We observe a drastic drop in performance as we scale the number of candidates used for negative samples. This is likely due to high class imbalance when training the model. This can be mitigated by finding the right class balance or by using appropriate loss re-weighting when updating the model. We leave investigating solutions to this issue as future work. We further tried to train our model with all the classes in our dataset and not simply the top n classes. Even the validation is done on all the classes. This is a fair problem to train on validation prediction step is exposed to all the classes. The results obtained with such a setting is quite different though.
| Num candidates | Overall accuracy |
|---|---|
| 10 | 2.8 |
| 250 | 12.5 |
Table 3. shows the results of Question-Answer alignment model on VQA sampled val split with the setting mentioned above. We ablate on different values of num candidates we select for our approach. Using 10 candidates for training and 250 candidates for validation we achieve 2.8% accuracy on the evaluation split which is 10% worse when compared to using 250 candidates for training and validation. This is because at the training time the model was not exposed to all the classes with 10 candidates and hence, it was very difficult for the model to predict correct classes during validation. Also, due to contrastive learning model learns to not predict most frequent classes as they were always negatively sampled. Hence, we get a drastic drop in performance. This can be mitigated by finding the right class balance or by using appropriate loss re-weighting when updating the model.
N-way classification using CLIP representations
As a simple upper-bound we set up a vanilla N-way classification baseline using frozen CLIP representations. We use a simple learnable 2-layer MLP that takes Image and Text CLIP embeddings as input and learns to predict answer using N-way classification head. This baseline leverages rich CLIP representations and learns a simple mapper that can map question and an image to answer (Figure 6). 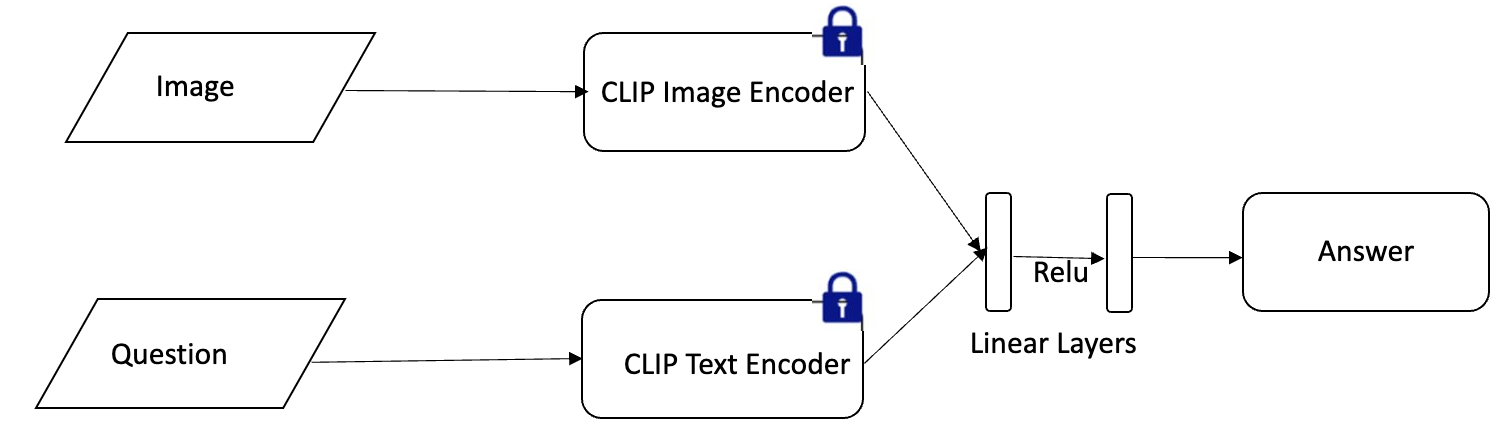
| Method | Overall accuracy |
|---|---|
| Zero-shot (unsupervised) | 2.85 |
| Question-Answer alignment (supervised) | 24.69 |
| N-way classification (supervised) | 49.27 |
(3.) Comparison of performance of proposed approaches on VQA sampled val
Table. 4 shows comparison of proposed approaches on VQA sampled val dataset. Our zero-shot baseline (row 1) achieves 2.85% val accuracy overall which is 46.42% worse when compared to N-way classification baseline (row 3). Next, learning a simple 2-layer MLP for Question-Answer alignment (row 2) improves overall accuracy over our zero-shot baseline (row 1) by 21.84% but it’s 24.58% worse compared to our N-way classification (row 3) baseline.
The comparison with our supervised upper-bound baseline shows that there is a lot of room for improvement for both of our approaches. In order to improve zero-shot VQA performance we need to improve our prompts and how we sample answers based on questions. Next, to improve our Question-Answer alignment model we can focus on improving our MLP model by using a better alignment network, better negative sampling strategy with loss appropriate re-weighting. These results establish a promising direction for a solution to VQA using CLIP.
Comparison with state-of-the-art baselines
Next, we compare performance of our proposed baselines with state-of-the-art few-shot CLIP baselines. Specifically, we compare with QIP (Question Irrelevant Prompt) and TAP-C (Template-Answer-Prompt then CLIP discrimination pipeline).
QIP
QIP explored directly prompting the CLIP models for VQA task. They used a “question: [question text] answer: [answer text]” template, together with prompt engineering of image classification, to prepare prompts. The resuling prompts are irrelevant of questions.
TAP-C
TAP-C uses a combination of automated template generation and common sense answer filtering to improve zero-shot VQA performance. They use a Large Language Model (T5) and dependency parsing to automatically convert the question into a template, for example, a question “What is the species of flower in the picture?” is converted to “The species of flower in the picture is [mask]?”. As common sense, “the species of a flower” can never be a vase. TAP-C then leverages pre-trained lanugage models to filter out less likely answers as it would have positive influence on final question answering performance. Once TAP-C gets a filtered set of answers they replace [mask] with all candidate answers to generate candidate prompts.
| Method | Overall accuracy |
|---|---|
| QIP | 21.26 |
| TAP-C | 38.72 |
| Zero-shot (unsupervised) | 2.85 |
| Question-Answer alignment (supervised) | 24.69 |
| N-way classification (supervised) | 49.27 |
(4.) Comparison of performance of proposed approaches with state-of-the-art VQA baselines
We compare our prompt based approaches with state-of-the-art zero-shot CLIP VQA baselines in Table. 4. First, our vanilla Zero-Shot baseline (row 3) that uses a simple prompt without any common-sense filtering and prompt engineering achieves 2.85% overall accuracy on VQA val split which is 18.41% worse compared to QIP (row 1) and 35.87% worse compared to TAP-C (row 2). We attribute such low performance to naive answer candidate selection heuristic (based on answer frequency in train set). As shown in TAP-C (row 2), improving on answer filtering based on common sense further helps improve zero-shot performance. Incorporating better answer filtering methods should help improve performance of our zero-shot baseline (row 3). Next, our Question-Answer alignment baseline (row 4) achieves 24.69% overall accuracy which is 3.43% better compared to QIP (row 1) and 14.03% worse compared to TAP-C (row 2). Our results suggest that learning a alignment model even with a naive candidate answer sampling strategy and simple prompts help improve over manually engineered prompts as shown in QIP. But learning a simple alignment model is not enough to learn complex candidate answer filtering i.e. our alignmen model eventhough it improves over a zero-shot baseline (QIP) it doesn’t perform as well when we compare it to a baseline that samples candidates based on common sense (TAP-C) implying that learning common-sense based filtering is not trivial for the proposed alignment model and it suffers from noisy samples in answer candidates. Finally, we show that existing state-of-the-art zero-shot CLIP baselines still have a room for improvement when compared to a simple supervised baseline (row 5) that uses CLIP representations. We find that a simple supervised baseline achieves 49.27% overall accuracy which has 28.01% better overall accuracy than QIP (row 1) and 10.55% better overall accuracy than TAP-C (row 2). This suggests we need more sophisticated zero-shot baselines to outperform simple supervised baselines on VQA dataset.
References
[1] S. Antol et al., “Vqa: Visual question answering,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2425–2433.
[2] Y Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering. In Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[3] A. Radford et al., Learning Transferable Visual Models From Natural Language Supervision. 2021.
[4] O. Patashnik, Z. Wu, E. Shechtman, D. Cohen-Or, and D. Lischinski, “StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct. 2021, pp. 2085–2094.
[5] H. Xu, K. He, B. A. Plummer, L. Sigal, S. Sclaroff, and K. Saenko, “Multilevel language and vision integration for text-to-clip retrieval,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2019, vol. 33, no. 1, pp. 9062–9069.
[6] M. Narasimhan, A. Rohrbach, and T. Darrell, “CLIP-It! language-guided video summarization,” *Advances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021.
[7] D. Gurari et al., “Vizwiz grand challenge: Answering visual questions from blind people,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 3608–3617.
[8] H. Song et al., CLIP Models are Few-shot Learners: Empirical Studies on VQA and Visual Entailment. 2022.
Proposed timeline and responsibilities