
ARDS Literature Survey
Published:
Table of Contents
- Few-Shot Text Classification
- Text classification from few training examples
- Zero-shot and few-shot learning in natural language processing
- Zero-Shot Learning in Modern NLP
- Few-Shot Transfer Learning for Text Classification With Lightweight Word Embedding Based Models - 2019
1. Few-Shot Text Classification
Article : https://few-shot-text-classification.fastforwardlabs.com/
This article uses a Zmap based approach to map the sentence level BERT based embedding to the Word2Vec based word embeddings for labels.
Such mapping provides a common ground for the sentences and labels to be able to compute the cosine distance correctly. 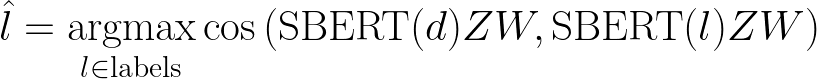 Hence, such kind of technique is effective for “on-the-fly” or “zero-shot” training.
Hence, such kind of technique is effective for “on-the-fly” or “zero-shot” training.
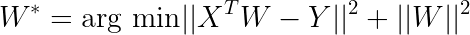
Additionally, by adding a regularizer term to force to the weight matrix to be as close to identity matrix helps in few-shot learning as well. 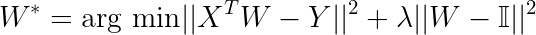
The datasets explored here are : AG News and Reddit
Few limitations
- Validation can be challenging
- Meaningful labels are a necessity
- Supervised models are still better
2. Text classification from few training examples
Article : https://maelfabien.github.io/machinelearning/NLP_5/#
This article proposes to use pre-trained models for classification in case of few-shot learning. It says there are several approaches to few shot learning in recent papers :
- either use a Siamese Network based on LSTMs rather than CNNs, and use this for One-shot learning
- learn word embeddings in one-shot or few-shot and classify on top
- or use a pre-trained word / document embedding network, and build a metric on top
The article further explores method 3, using average of the embeddings to denote each class and finding closest distance during testing. Another method the article uses is to use KNNs after the embeddings to determine the label for the test class.
3. Zero-shot and few-shot learning in natural language processing
Article : https://aixplain.com/2021/09/23/zero-shot-learning-in-natural-language-processing/
This article uses the natural language inference (NLI) task, where given a premise and a hypothesis we say if the hypothesis is true (entailment), false (contradiction), or undetermined (neutral).
Consider the premise as the text you would like to classify and the hypothesis as a sentence with this structure: “This text is about {label_name}”, where label_name is the label you want to predict, the NLI model predicts probabilities for entailment, contradiction and neutral and that value tells if the text is classified as the provided label.
4. Zero-Shot Learning in Modern NLP
Article : https://joeddav.github.io/blog/2020/05/29/ZSL.html
This article explores three methods :
- Zmap based approach as discussed in 1.
- NLI based approach as discusses in 3.
Classification as cloze task :
Pattern-Exploiting Training (PET) reformulates text classification as a cloze task. A cloze question considers a sequence which is partially masked and requires predicting the missing value(s) from the context. PET requires a human practitioner to construct several task-appropriate cloze-style templates. A pre-trained masked language model is then tasked with choosing the most likely value for the masked (blank) word from among the possible class names for each cloze sentence.
The result is a set of noisy class predictions for each data point. This process alone serves as a basic zero-shot classifier. In addition, the authors introduce a sort of knowledge distilation procedure. After generating a set of predictions from the cloze task, these predicted values are used as proxy labels on which a new classifier is trained from scratch.
Although PET significantly outperforms the other methods described here, it also makes use of data which the other approaches do not assume access to: multiple task-specific, hand-crafted cloze sentences and a large set of unlabeled data for the distilation/self-learning step.
5. Few-Shot Transfer Learning for Text Classification With Lightweight Word Embedding Based Models
Paper : https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8693837
Problem Statement
Paper explores few-shot transfer learning methods for text classification with lightweight word embedding based models.
Related Work
- Transfer Learning
- Meta learning
- Siamese/Relation based networks
- Text Classification
- Deep Averaging Networks
Method
- Word embeddings is done using word2vec
- Simple Word Embeddings Based Models
- Mean pooling
- Max pooling
- Concatenated pooling
- Hierarchical pooling
- Modified Hierarchical pooling
- SVM classification
Dataset
Netease and Cnews are two public Chinese text classification datasets. There are 6 categories and only 4000 samples for each category in Netease. Cnews is a subset of the THUCNews dataset, a Chinese text classification dataset produced by Natural Language Processing and Computational Social Science Lab, Tsinghua University. There are 10 categories with 5000/500/1000 samples each category for train/validation/test. The samples in Netease and Cnews are long text documents with 582 and 530 tokens on average, respectively. About the English text datasets, AG News and Yahoo are two topic categorization datasets with 4 and 10 categories, respectively. The average word numbers are 43 for AG News and 104 for Yahoo. DBpedia is an ontology classification dataset with 14 categories and 57 words each sample on average. For few-shot transfer learning, M sampled classes are firstly selected and then N shot samples and Q query samples are randomly selected from each of the sampled classes, which is called M-way N-shot Q-query. For example, in 5-way 1-shot 15-query settings, there are 1 support and 15 testing samples for each of the 5 sampled classes in each evaluation episode.
Metrics
- Accuracy